GPT-5.4: OpenAIs neues Flaggschiff-Modell im Detail
OpenAI hat mit GPT-5.4 ein Modell veröffentlicht, das Reasoning, Programmierung und Computernutzung erstmals in einem Frontier-Modell vereint. Was das für IT-Profis in der Schweiz bedeutet.
Am 5. März 2026 hat OpenAI GPT-5.4 veröffentlicht – und diesmal ist der Sprung grösser, als die Versionsnummer vermuten lässt. Wer in den letzten Monaten die rasante Modell-Kadenz von OpenAI verfolgt hat (GPT-5.2, dann GPT-5.3-Codex als spezialisiertes Programmiermodell), der fragt sich vielleicht: Brauche ich wirklich schon wieder ein neues Modell? Die kurze Antwort: Ja, und zwar aus einem ziemlich fundamentalen Grund. GPT-5.4 ist das erste Frontier-Modell, das Reasoning, Programmierung, native Computernutzung und agentische Workflows in einem einzigen Paket vereint. Kein Zusammenstöpseln verschiedener Modelle mehr, kein Wechsel zwischen Codex für Code und einem anderen Modell für Analyse.
Für IT-Fachkräfte und Entscheider in der Schweiz ist das Release besonders relevant – nicht weil OpenAI plötzlich Schweizerdeutsch spricht, sondern weil die neuen Fähigkeiten genau dort ansetzen, wo professionelle Arbeit in Beratung, Finanzdienstleistung und Softwareentwicklung stattfindet: bei Tabellen, Präsentationen, komplexen Recherchen und vor allem bei der Automatisierung mehrstufiger Workflows. GPT-5.4 liefert laut OpenAI «mit weniger Hin und Her genau das, wonach du gefragt hast». Ein Versprechen, das wir uns genauer anschauen.
Dieser Artikel ordnet die wichtigsten Neuerungen ein – von den Benchmark-Zahlen über die neue Tool-Suche bis hin zu den API-Preisen – und beleuchtet, was GPT-5.4 konkret für Entwicklerteams, CTOs und den Schweizer IT-Arbeitsmarkt bedeutet.
Das grosse Bild: Warum GPT-5.4 mehr ist als ein inkrementelles Update
Zunächst eine Einordnung, die OpenAI selbst nur zwischen den Zeilen liefert: Es gab kein GPT-5.3 als Mainline-Modell. GPT-5.3-Codex war ein spezialisiertes Programmiermodell – herausragend beim Coden, aber eben kein Allrounder. GPT-5.4 integriert nun die branchenführenden Programmierfähigkeiten von GPT-5.3-Codex direkt in das Hauptmodell und ergänzt sie um Fähigkeiten, die vorher schlicht nicht existierten. OpenAI nennt es «das erste Mainline-Reasoning-Modell, das die Frontier-Programmierfähigkeiten von GPT-5.3-Codex integriert». Der Versionssprung von 5.2 auf 5.4 soll genau diesen Quantensprung widerspiegeln.
Was «für professionelle Arbeit entwickelt» konkret heisst, zeigt sich an einem Detail, das leicht übersehen wird: GPT-5.4 ist OpenAIs bisher effizientestes Reasoning-Modell. Es braucht deutlich weniger Tokens als GPT-5.2, um zum gleichen Ergebnis zu kommen. Weniger Tokens bedeuten nicht nur niedrigere Kosten – sie bedeuten auch schnellere Antworten und weniger Rauschen im Kontext. Für Entwickler, die Agenten bauen, ist das ein handfester Vorteil. Für Endnutzer in ChatGPT bedeutet es: Das Modell kommt schneller zum Punkt und bleibt dabei präziser.
Dazu kommt die Kontextlänge von bis zu 1 Million Tokens. Das ist kein Marketing-Gag – es ermöglicht Agenten, über lange Zeiträume hinweg zu planen, auszuführen und ihre eigene Arbeit zu verifizieren. Stellen Sie sich einen Agenten vor, der ein ganzes Softwareprojekt durcharbeitet, nicht nur eine einzelne Funktion. Oder einen Recherche-Agenten, der dutzende Quellen systematisch auswertet, ohne den Faden zu verlieren. Genau dafür ist diese Kontextlänge gedacht.
Wissensarbeit auf neuem Niveau: Tabellen, Präsentationen und weniger Halluzinationen
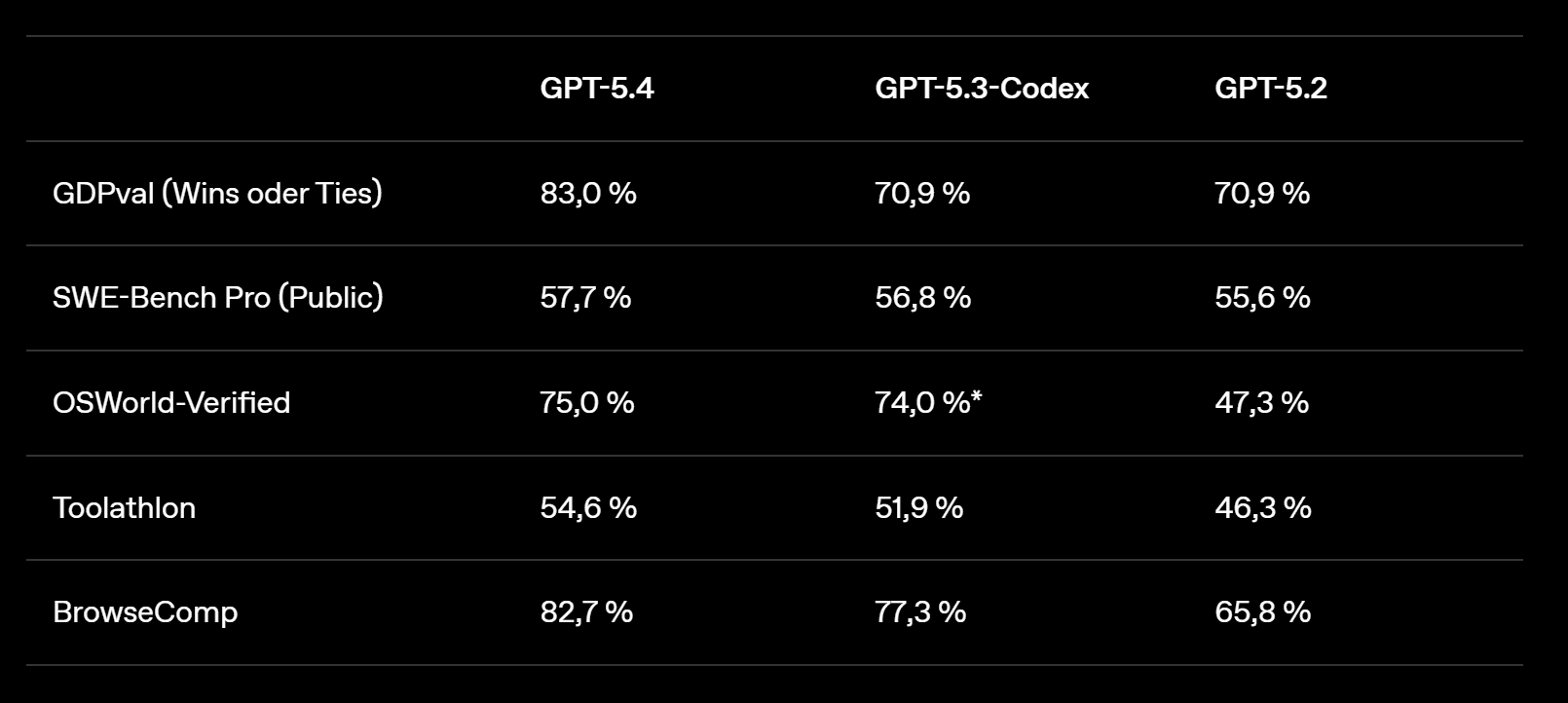
Hier wird es für alle spannend, die nicht primär Code schreiben. OpenAI hat einen neuen Benchmark namens GDPval entwickelt, der die Fähigkeit von KI-Modellen testet, genau definierte Wissensarbeit in 44 verschiedenen Berufen zu leisten – von Verkaufspräsentationen über Buchhaltungstabellen bis hin zu Notfallplänen und Fertigungsdiagrammen. GPT-5.4 erreicht oder übertrifft Branchenfachleute in 83 % der Vergleiche. Bei GPT-5.2 waren es noch 71 %. Das ist kein marginaler Fortschritt – das ist ein Sprung von 12 Prozentpunkten, der in der Praxis den Unterschied zwischen «brauchbar» und «beeindruckend» ausmachen kann.
- Tabellenmodellierung (Investment-Banking-Aufgaben): 87,5 % Genauigkeit bei GPT-5.4 vs. 68,4 % bei GPT-5.2 – ein Sprung, der für Schweizer Finanzdienstleister und Berater direkt relevant ist
- Präsentationen: Menschliche Bewerter bevorzugten in 68 % der Fälle die Ergebnisse von GPT-5.4 – stärkere Ästhetik, mehr visuelle Vielfalt, bessere Nutzung der Bildgenerierung
- Halluzinationen: 33 % weniger falsche Einzelaussagen und 18 % weniger fehlerhafte Gesamtantworten im Vergleich zu GPT-5.2 – GPT-5.4 ist OpenAIs bisher faktentreuestes Modell
- Neue Plugins «ChatGPT für Excel» und «ChatGPT für Google Sheets» als Teil der Initiative OpenAI für Finanzdienstleistungen
- Verbesserte Dokumentenerstellung und -bearbeitung direkt in ChatGPT, Codex und über die API
“GPT-5.4 ist das beste Modell, das wir je ausprobiert haben. Es steht jetzt an der Spitze der Rangliste unseres APEX-Agents-Benchmarks, der die Modellleistung im Bereich professioneller Dienstleistungen misst. Es tut sich besonders bei der Erstellung von Deliverables mit langem Zeithorizont wie Foliensätzen für Präsentationen, Finanzmodellen und juristischen Analysen hervor und liefert Spitzenleistung, während es schneller und zu geringeren Kosten läuft als konkurrierende Frontier-Modelle.”
— Brendan Foody, CEO von Mercor
Was viele nicht wissen: Die Reduktion von Halluzinationen ist nicht einfach ein Nebeneffekt besseren Trainings. OpenAI hat gezielt an der Faktentreue gearbeitet – anhand anonymisierter Prompts, bei denen Nutzer sachliche Fehler gemeldet hatten. Für Schweizer Unternehmen, die KI in regulierten Branchen wie Finanzdienstleistung oder Pharma einsetzen wollen, ist genau diese Verlässlichkeit der entscheidende Faktor. Ein Finanzmodell mit 33 % weniger Fehlern ist nicht einfach «etwas besser» – es ist der Unterschied zwischen einem Tool, dem man vertrauen kann, und einem, das man ständig kontrollieren muss.
Computernutzung: Wenn die KI den Desktop bedient
Jetzt kommen wir zu dem Feature, das bei vielen IT-Profis gleichzeitig Begeisterung und ein leichtes Unbehagen auslösen dürfte. GPT-5.4 ist das erste Allzweckmodell von OpenAI mit nativen Computernutzungs-Fähigkeiten. Das Modell kann Maus- und Tastaturbefehle ausführen, Screenshots interpretieren und damit echte Software bedienen – nicht über APIs, sondern so, wie ein Mensch vor dem Bildschirm sitzt. Es schreibt Code, um Computer über Bibliotheken wie Playwright zu steuern, und reagiert auf das, was es auf dem Bildschirm sieht.

Die Benchmark-Zahlen sind bemerkenswert. Bei OSWorld-Verified, einem Test, der misst, wie gut ein Modell anhand von Screenshots und Tastatur-/Mausaktionen durch eine Desktop-Umgebung navigiert, erreicht GPT-5.4 eine Erfolgsquote von 75,0 %. Zum Vergleich: GPT-5.2 kam auf 47,3 %, und die menschliche Leistung liegt bei 72,4 %. Das Modell ist also nicht nur besser als sein Vorgänger – es übertrifft erstmals den menschlichen Durchschnitt bei der Computernutzung. Auf WebArena-Verified (Browsernutzung) erreicht es 67,3 %, bei Online-Mind2Web sogar 92,8 % allein mit Screenshot-basierter Beobachtung.
- Neue Bildeingabe-Detailstufe «Original»: Unterstützt bis zu 10 Mio. Pixel oder 6K-Auflösung für volle Wiedergabetreue bei dichten, hochauflösenden Bildern
- Verbessertes Dokumenten-Parsing: Fehlerwert bei OmniDocBench von 0,140 (GPT-5.2) auf 0,109 (GPT-5.4) gesenkt
- Steuerbare Agenten: Entwickler können das Verhalten über Entwicklernachrichten anpassen und sogar Sicherheitsrichtlinien mit benutzerdefinierten Bestätigungsrichtlinien konfigurieren
- Neue experimentelle Codex-Fähigkeit «Playwright (Interactive)»: Codex kann Web- und Electron-Apps visuell debuggen – auch Apps, die es gerade selbst entwickelt
- MMMU-Pro (visuelles Verständnis): 81,2 % Erfolgsquote vs. 79,5 % bei GPT-5.2 – mit einem Bruchteil der Tokens zum Nachdenken
Für Entwicklerteams in der Schweiz, die an Automatisierungslösungen arbeiten, eröffnet das völlig neue Möglichkeiten. Denken Sie an Legacy-Systeme ohne API – und davon gibt es in der Schweizer Banken- und Versicherungslandschaft bekanntlich einige. Ein Agent, der diese Systeme über die Benutzeroberfläche bedienen kann, ist kein Science-Fiction-Szenario mehr. Er ist ein API-Aufruf entfernt.
Tool-Suche und agentische Workflows: Der stille Game-Changer
Über die Computernutzung wird viel geredet werden. Aber der eigentliche Game-Changer für Entwickler, die produktive KI-Agenten bauen, ist möglicherweise die neue Tool-Suche. Das Problem kennt jeder, der mit der OpenAI API und vielen Tools gearbeitet hat: Bisher wurden sämtliche Tool-Definitionen von Anfang an in den Prompt gepackt. Bei Systemen mit dutzenden Tools konnten das locker Tausende oder Zehntausende Tokens sein – Tokens, die Geld kosten, den Kontext belasten und die Antworten verlangsamen, obwohl das Modell die meisten dieser Tools nie braucht.
GPT-5.4 löst das elegant: Das Modell erhält eine schlanke Übersichtsliste der verfügbaren Tools plus eine Suchfunktion. Braucht es ein bestimmtes Tool, schlägt es dessen Definition nach und hängt sie genau in dem Moment an den Kontext an. Klingt simpel, hat aber massive Auswirkungen. In einem Test mit 250 Aufgaben aus dem MCP-Atlas-Benchmark von Scale – mit allen 36 MCP-Servern aktiviert – reduzierte die Tool-Suche die Token-Nutzung um 47 % bei exakt gleicher Genauigkeit. Das ist nicht nur ein Effizienzgewinn, das verändert die Wirtschaftlichkeit von KI-Agenten grundlegend.
- Toolathlon-Benchmark: GPT-5.4 erreicht 54,6 % Genauigkeit vs. 46,3 % bei GPT-5.2 – und das in weniger Runden, also mit geringerer Latenz
- MCP-Server-Integration: 47 % weniger Token-Verbrauch bei gleicher Genauigkeit durch intelligente Tool-Suche statt Kontext-Überladung
- Kontextlänge von 1 Mio. Tokens: Agenten können über lange Zeiträume planen, ausführen und verifizieren, ohne den Faden zu verlieren
- Verbesserte parallele Tool-Aufrufe: Weniger «Tool Yields» (Unterbrechungen zum Warten auf Tool-Antworten) bedeuten niedrigere Latenz in der Praxis
- BrowseComp (agentische Websuche): 82,7 % bei GPT-5.4 vs. 65,8 % bei GPT-5.2 – die Pro-Variante erreicht sogar 89,3 %
“Mit der Tool-Suche erhält GPT-5.4 stattdessen eine schlanke Liste verfügbarer Tools zusammen mit einer Tool-Suchfunktion. Wenn das Modell ein Tool verwenden muss, kann es die Definition dieses Tools nachschlagen und sie in diesem Moment an das Gespräch anhängen.”
— OpenAI, Produktankündigung GPT-5.4
Interessant ist auch die verbesserte Websuche. Bei BrowseComp – einem Benchmark, der misst, wie gut KI-Agenten hartnäckig im Web nach schwer auffindbaren Informationen suchen – legt GPT-5.4 um satte 17 Prozentpunkte gegenüber GPT-5.2 zu. In der Praxis heisst das: GPT-5.4 Thinking kann über mehrere Runden hinweg beharrlicher suchen, Informationen aus vielen Quellen zusammenführen und besonders bei «Nadel-im-Heuhaufen»-Fragen die relevantesten Quellen identifizieren. Für Research-Teams – ob in Zürich, Genf oder Basel – ist das ein spürbarer Unterschied.
Programmierung und Codex: Schneller, besser, und jetzt auch visuell
GPT-5.4 kombiniert die Programmier-Stärken von GPT-5.3-Codex mit den neuen Fähigkeiten in Wissensarbeit und Computernutzung. Auf dem SWE-Bench Pro erreicht es 57,7 % – auf Augenhöhe mit oder besser als GPT-5.3-Codex, aber mit deutlich geringerer Latenz über alle Reasoning-Aufwandsstufen hinweg. Das klingt nach einer kleinen Verbesserung, ist aber in der Praxis erheblich: Geringere Latenz bei gleicher oder besserer Qualität bedeutet, dass Entwickler im Flow bleiben können, statt auf das Modell zu warten.
- SWE-Bench Pro: 57,7 % Erfolgsquote – besser als GPT-5.3-Codex (56,8 %) und GPT-5.2 (55,6 %), bei niedrigerer Latenz
- Der /fast-Modus in Codex liefert bis zu 1,8-fache Geschwindigkeit bei gleicher Intelligenz – dasselbe Modell, nur schneller
- Besondere Stärke bei komplexen Frontend-Aufgaben: deutlich ästhetischere und funktionalere Ergebnisse als alle Vorgängermodelle
- Vorrangige Verarbeitung (Priority Processing) in der API ermöglicht dieselben hohen Geschwindigkeiten für Entwickler ausserhalb von Codex
- Neue «Playwright (Interactive)»-Fähigkeit: Codex kann Web- und Electron-Apps visuell debuggen, inklusive Apps, die es gerade selbst entwickelt
Übrigens: Die Kombination aus Computernutzung und Programmierung eröffnet ein Szenario, das vor einem Jahr noch absurd geklungen hätte. GPT-5.4 in Codex kann eine Web-App entwickeln, sie dann über Playwright starten und visuell testen – alles in einem Durchlauf. Bugs im Layout? Das Modell sieht sie auf dem Screenshot und fixt sie. Das ist nicht mehr «KI als Coding-Assistent», das ist «KI als Junior-Entwickler mit eigenem Bildschirm». Für Schweizer Softwarehäuser, die unter dem bekannten Fachkräftemangel leiden, könnte das ein echter Hebel sein – nicht als Ersatz für Entwickler, sondern als Multiplikator.
Sicherheit und Steuerbarkeit: Transparentes Denken, kontrollierbare Ausgaben
Mit grösserer Leistungsfähigkeit kommt grössere Verantwortung – und OpenAI scheint das bei GPT-5.4 ernst zu nehmen. Die Cyberfähigkeiten des Modells werden im Rahmen des Preparedness Framework als «Hoch» eingestuft, was einen vorsorglichen Bereitstellungsansatz nach sich zieht. Konkret bedeutet das: ein erweiterter Cybersicherheits-Stack, Überwachungssysteme, Trusted-Access-Kontrollen und die Möglichkeit, Anfragen mit höherem Risiko für bestimmte Kunden zu routen oder zu blockieren.
“Wir stellen fest, dass die Fähigkeit von GPT-5.4 Thinking, seine CoT zu kontrollieren, gering ist, was eine positive Eigenschaft für die Sicherheit ist und darauf hindeutet, dass dem Modell die Fähigkeit fehlt, sein Reasoning zu verbergen, und dass die CoT-Überwachung nach wie vor ein wirksames Sicherheitsinstrument ist.”
— OpenAI, Sicherheitsbericht GPT-5.4
- Neue Steuerbarkeit in ChatGPT: GPT-5.4 Thinking zeigt vorab seinen Denkplan an – Nutzer können die Richtung mitten in der Antwort anpassen, ohne von vorn zu beginnen
- Chain-of-Thought-Überwachung: Neue Open-Source-Evaluierung «CoT Controllability» zeigt, dass GPT-5.4 sein Reasoning kaum verschleiern kann – ein gutes Zeichen für Transparenz
- Dual-Use-Problematik bei Cyberfähigkeiten: Blockierung auf Anfrageebene bleibt aktiv, falsch-positive Ergebnisse werden schrittweise reduziert
- Verbessertes Kontextbewusstsein: Das Modell behält bei langen Arbeitsabläufen ein stärkeres Bewusstsein für frühere Schritte bei und bleibt kohärenter
- Weniger unnötige Ablehnungen und übermässig mit Vorbehalten versehene Antworten – bei gleichzeitig starkem Schutz vor Missbrauch
Die Steuerbarkeit ist ein Punkt, der in der Praxis oft unterschätzt wird. Wer schon mal eine komplexe Analyse von ChatGPT angefordert hat und nach 2000 Wörtern merkte, dass das Modell in die falsche Richtung gelaufen ist, kennt die Frustration. GPT-5.4 Thinking zeigt jetzt vorab seinen Arbeitsplan und erlaubt Korrekturen während der Generierung. Das klingt nach einem kleinen UX-Feature, spart aber in der Realität enorm viel Zeit – besonders bei Aufgaben, die mehrere Minuten Rechenzeit beanspruchen.
Verfügbarkeit, Preise und was das für den Schweizer IT-Markt bedeutet
GPT-5.4 Thinking ist ab sofort für ChatGPT Plus-, Team- und Pro-Nutzer verfügbar. Enterprise- und Edu-Kunden können den frühzeitigen Zugriff über die Admin-Einstellungen aktivieren. Die Pro-Variante GPT-5.4 Pro – für maximale Leistung bei den komplexesten Aufgaben – steht Pro- und Enterprise-Plänen zur Verfügung. In der API ist das Modell als gpt-5.4 respektive gpt-5.4-pro sofort nutzbar.
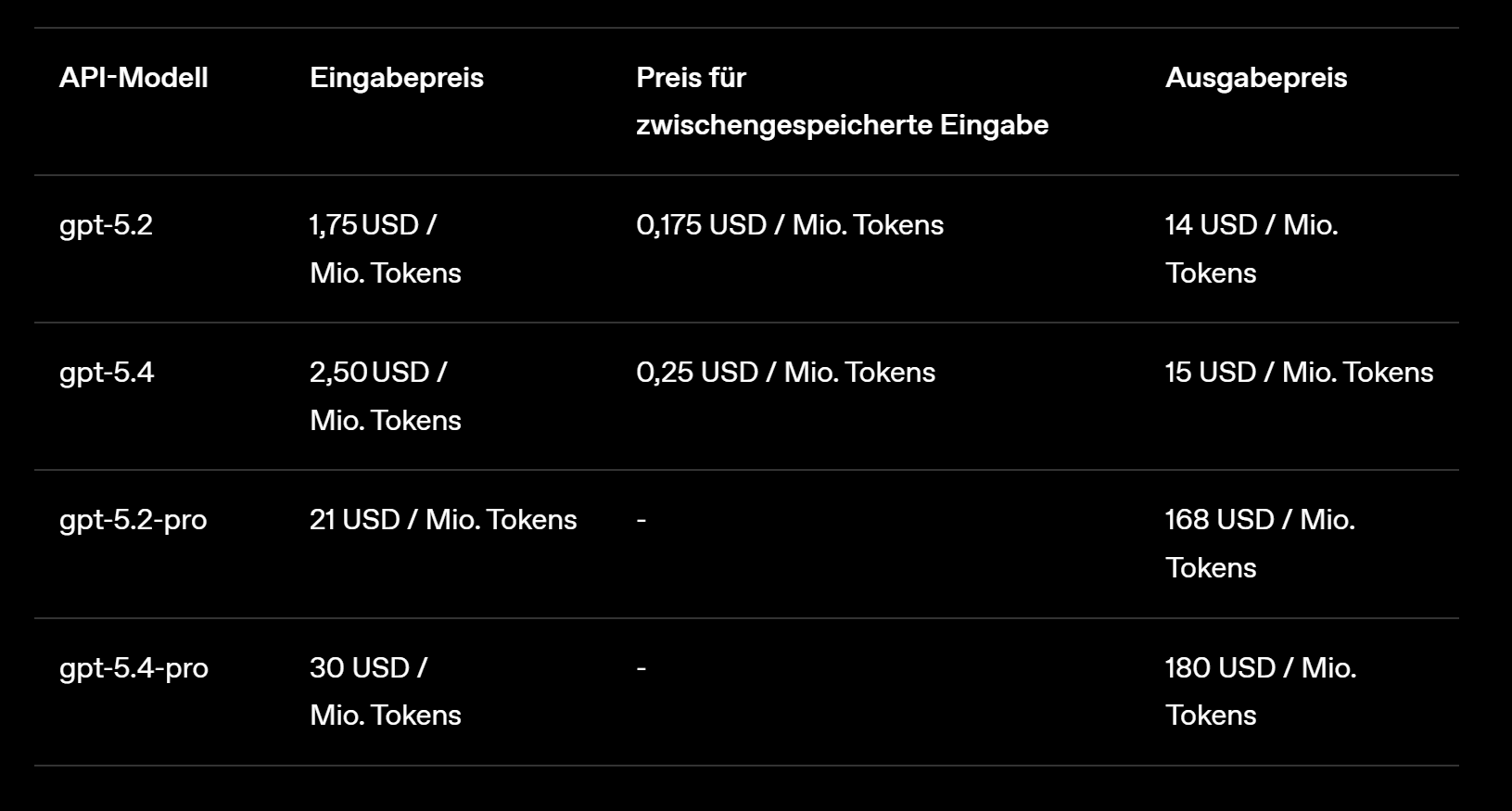
- gpt-5.4 Standard: 2,50 USD pro Mio. Input-Tokens, 0,25 USD für gecachte Eingaben, 15 USD pro Mio. Output-Tokens – teurer pro Token als GPT-5.2 (1,75 / 0,175 / 14 USD), aber effizienter in der Gesamtnutzung
- gpt-5.4-pro: 30 USD pro Mio. Input-Tokens, 180 USD pro Mio. Output-Tokens – für Aufgaben, bei denen maximale Qualität gefragt ist
- Batch- und Flex-Preisgestaltung zum halben Standard-API-Tarif verfügbar – interessant für Schweizer Unternehmen mit grossen Verarbeitungsvolumen
- Vorrangige Verarbeitung (Priority Processing) zum doppelten Standard-Tarif – für latenzempfindliche Anwendungen
- Die höhere Token-Effizienz von GPT-5.4 kompensiert den höheren Pro-Token-Preis bei vielen Aufgaben – OpenAI spricht von deutlich weniger Tokens pro gelöstem Problem
Spannend wird es bei der Frage, was das für den Schweizer IT-Markt bedeutet. Die neuen agentischen Fähigkeiten von GPT-5.4 – Computernutzung, Tool-Suche, 1-Million-Token-Kontext – schaffen eine Nachfrage nach Fachkräften, die es vor zwei Jahren noch nicht gab. Wer heute «AI Agent Engineer» oder «Prompt Architect» auf dem Lebenslauf stehen hat, wird sich vor Anfragen kaum retten können. Schweizer Unternehmen, die in regulierten Branchen arbeiten, brauchen zudem Leute, die nicht nur Agenten bauen, sondern auch deren Sicherheitsrichtlinien konfigurieren und die Compliance sicherstellen können.
Für IT-Abteilungen stellt sich eine strategische Frage: Lohnt es sich, bestehende Workflows auf GPT-5.4 umzustellen? Die Antwort hängt vom Use Case ab. Wer bereits GPT-5.2 in der API nutzt, profitiert von der höheren Token-Effizienz und den besseren agentischen Fähigkeiten – der Umstieg ist ein API-Parameter-Wechsel. Wer bisher auf GPT-5.3-Codex für Programmieraufgaben gesetzt hat, bekommt mit GPT-5.4 die gleiche Codier-Qualität plus alles andere obendrauf. Und wer noch gar nicht mit KI-Agenten arbeitet: Die Einstiegshürde war noch nie so niedrig wie jetzt.
Ein Modell, das die Spielregeln verschiebt
GPT-5.4 ist nicht einfach das nächste Modell in einer immer schnelleren Release-Kadenz. Es markiert einen Punkt, an dem die Grenzen zwischen «KI-Chatbot», «Programmierassistent» und «autonomer Software-Agent» verschwimmen. Ein Modell, das Code schreibt, Computer bedient, Tabellen modelliert, im Web recherchiert und dabei seinen eigenen Denkprozess transparent macht – das ist qualitativ etwas anderes als alles, was wir bisher gesehen haben.
Für IT-Profis in der Schweiz heisst das: Die Fähigkeit, mit diesen Modellen zu arbeiten – sie zu steuern, ihre Grenzen zu kennen, sie in bestehende Systeme zu integrieren – wird zur Kernkompetenz. Nicht irgendwann, sondern jetzt. Wer sich heute mit der Tool-Suche-API, den Computernutzungs-Fähigkeiten und den Sicherheitskonfigurationen von GPT-5.4 auseinandersetzt, baut sich einen Vorsprung auf, der in sechs Monaten Gold wert sein wird. Die Modelle werden nicht langsamer. Die Frage ist nur, ob man mitzieht.
ITBoard Redaktion
itboard.ch