Die Herausforderungen und Chancen moderner KI-Modelle: Ein kritischer Blick auf GPT-5.2
Entdecken Sie die Leistungsfähigkeit und Grenzen von GPT-5.2. Ein tiefer Einblick in die Auswirkungen auf die IT-Branche in der Schweiz.
In der Welt der Künstlichen Intelligenz (KI) jagt eine Innovation die nächste. Doch mit jedem neuen Modell entstehen nicht nur Chancen, sondern auch Herausforderungen, die es zu bewältigen gilt. GPT-5.2, das jüngste Modell von OpenAI, hat große Erwartungen geweckt. Es verspricht erhebliche Fortschritte in der Intelligenz und Effizienz. Aber wie sieht es in der Praxis aus? Sind diese Fortschritte wirklich so bedeutend, wie sie scheinen? Lassen Sie uns einen kritischen Blick auf die Leistungsfähigkeit von GPT-5.2, seine Benchmarks, den Einfluss von Feedback-Schleifen und die wirtschaftlichen Überlegungen werfen, die bei der Nutzung dieser Technologie berücksichtigt werden sollten.
Die Leistungsfähigkeit von GPT-5.2 wird als bahnbrechend beschrieben. OpenAI behauptet, dass es in der Lage ist, komplexe Aufgaben in der Wissensarbeit zu bewältigen. Doch was bedeutet das konkret? In standardisierten Tests zeigt das Modell beeindruckende Ergebnisse, doch die Reaktionen der Nutzer sind gemischt. Einige empfinden das Modell als "langweilig" und "zu sicher". Diese Diskrepanz zwischen theoretischer Leistungsfähigkeit und praktischer Anwendung wirft Fragen zur tatsächlichen Nützlichkeit auf.

Leistungsfähigkeit von GPT-5.2
GPT-5.2 wird als das bislang leistungsfähigste Modell von OpenAI beworben. Es zeigt in vielen Benchmarks herausragende Leistungen, insbesondere bei klar definierten Aufgaben aus dem Bereich der Wissensarbeit. Laut OpenAI spart es durchschnittlichen Nutzern 40–60 Minuten pro Tag ein. Doch diese theoretischen Vorteile müssen in der Praxis bestehen. Die Frage ist, ob GPT-5.2 tatsächlich die Erwartungen der Nutzer erfüllt.
“„Es ist ein aufregender und bemerkenswerter Sprung in der Ausgabequalität … [es] scheint von einem professionellen Unternehmen mit Personal erstellt worden zu sein.“”
— OpenAI
Interessant ist auch, dass GPT-5.2 in der Lage ist, komplexe, mehrstufige Projekte zu bearbeiten. Die Fähigkeit, lange Kontexte zu verstehen und Tools effektiv zu nutzen, macht es zu einem wertvollen Werkzeug in der professionellen Wissensarbeit. Doch trotz dieser Fähigkeiten gibt es Kritikpunkte, die nicht ignoriert werden sollten.
Benchmarks im Vergleich zur Praxis
Während GPT-5.2 in standardisierten Tests hervorragende Leistungen zeigt, unterscheiden sich die Ergebnisse oft erheblich bei realen Aufgaben. Besonders bei komplexen Schreib- und Planungsaufgaben kann das Modell an seine Grenzen stoßen. Ein von uns entwickelter Skate-Bench-Test verdeutlichte, dass die Ergebnisse stark variieren, je nachdem, ob es um räumliches Denken oder kreative Namensgebung geht.
Ein weiterer Aspekt, den viele übersehen, ist, dass die Benchmarks zwar beeindruckend sind, aber nicht immer die realen Herausforderungen widerspiegeln, denen sich Nutzer in der Praxis gegenübersehen. Die Fähigkeit, sich an spezifische Anforderungen anzupassen, ist entscheidend, um den tatsächlichen Nutzen eines Modells zu beurteilen.
Die Rolle von Feedback-Schleifen
Ein wesentlicher Faktor für die Verbesserung der Modellleistung ist das Feedback. Modelle wie GPT-5.2 zeigen eine deutliche Steigerung der Ausgabequalität, wenn gezielte Rückmeldungen gegeben werden. Dies ist besonders im redaktionellen Bereich von Vorteil, wo der Feinschliff entscheidend ist.
Claude und Opus reagieren unterschiedlich sensibel auf externes Review, was die Wahl des richtigen Modells für spezifische Aufgaben beeinflussen kann. Die Möglichkeit, durch Feedback besser zu werden, ist eine der größten Stärken von GPT-5.2, aber auch eine Herausforderung, da es eine kontinuierliche Interaktion mit dem Modell erfordert.
“„GPT-5.2 ist intelligenter, Opus 4.5 besser, Gemini 3 Pro eindeutig problemhafter.“”
— TechRadar
Kosten-Nutzen-Analyse
Die Nutzung von Hochleistungsmodellen wie GPT-5.2 ist mit höheren Kosten verbunden. Diese müssen jedoch im Verhältnis zum tatsächlichen Nutzen betrachtet werden. In vielen Fällen liefern sie nur begrenzte Mehrwerte, was dazu führt, dass Unternehmen effiziente Alternativen in Betracht ziehen, die bei geringeren Kosten eine hohe Effizienz bieten.
Ein weiterer Punkt ist die Diskrepanz zwischen Preis und wahrgenommenem Nutzen. Während die Kosten pro Abfrage bei GPT-5.2 höher sind, bieten kompositorische Werkzeuge wie Composer eine Effizienzsteigerung, die den Preis rechtfertigt. Unternehmen müssen abwägen, ob die Investition in ein solches Modell den gewünschten Mehrwert bringt.
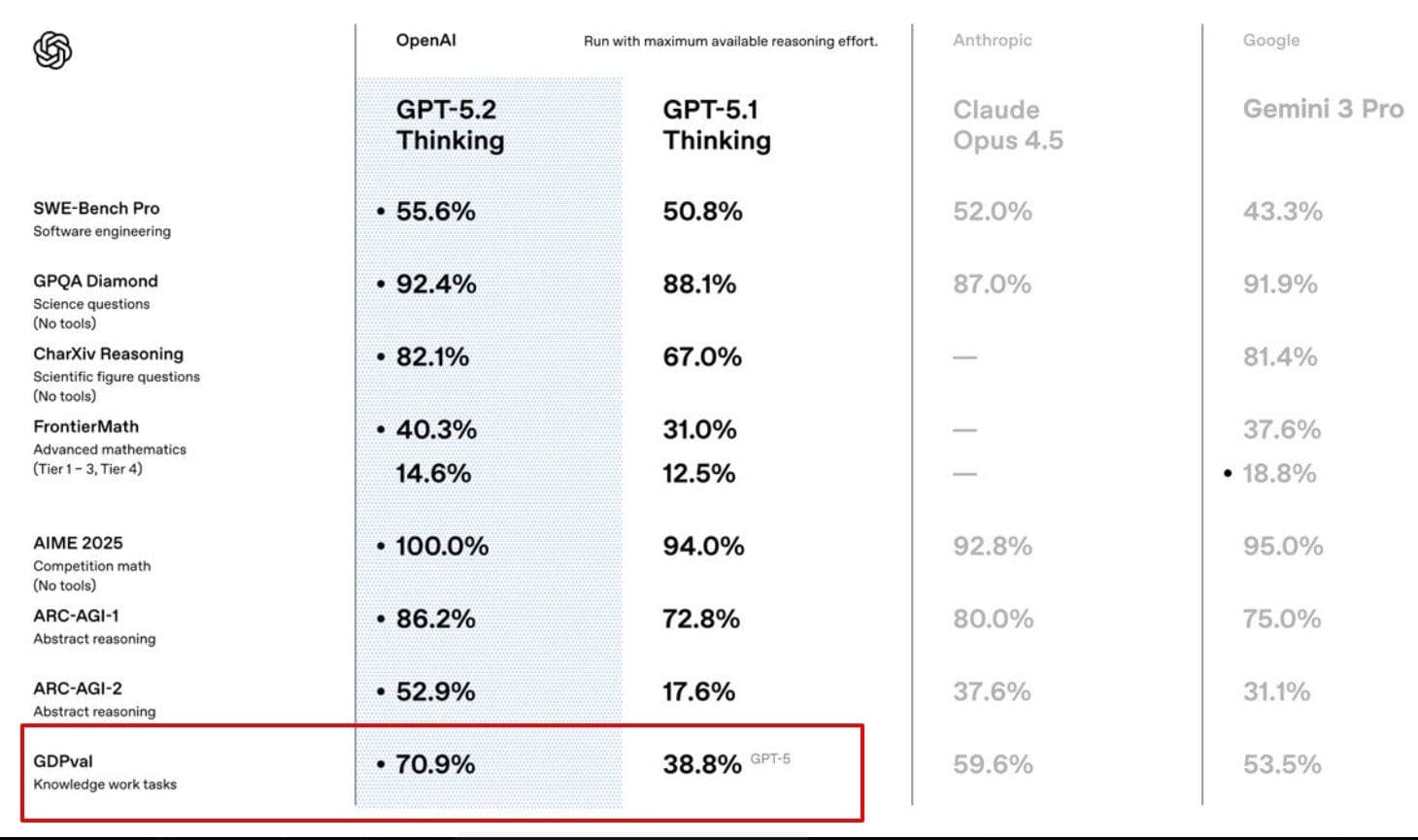
Wirtschaftliche Dynamik und Modellwahl
Die wirtschaftliche Dynamik der KI-Modelle beeinflusst die Entscheidungen von IT-Unternehmen erheblich. Modelle wie Opus 4.5 erweisen sich als kosteneffektiver bei gleichzeitig hoher Zufriedenheit der Nutzer. Im Gegensatz dazu stehen Modelle wie Gemini 3 Pro, die trotz hoher Kosten oft enttäuschende Ergebnisse liefern.
Unternehmen in der Schweiz müssen daher sorgfältig abwägen, welches Modell am besten zu ihren Bedürfnissen passt. Die Wahl eines Modells sollte nicht nur auf der Leistungsfähigkeit basieren, sondern auch auf der Wirtschaftlichkeit und der Zufriedenheit der Nutzer.
Ein Blick in die Zukunft
Abschließend lässt sich sagen, dass GPT-5.2 zweifellos Fortschritte bringt, aber auch klare Grenzen aufweist. Die Fähigkeit, auf Feedback zu reagieren, ist eine der größten Stärken, während die Kostenfrage weiterhin eine Herausforderung darstellt. Die Zukunft der KI-Entwicklung wird zunehmend von Zuverlässigkeit, Geschwindigkeit und praxistauglichem Handling geprägt sein.
Unternehmen sollten Modelle nach Nützlichkeit und Vorhersagbarkeit auswählen, um im dynamischen IT-Umfeld der Schweiz erfolgreich zu bleiben. Die kontinuierliche Weiterentwicklung und Anpassung an die Bedürfnisse der Nutzer wird entscheidend für den Erfolg moderner KI-Modelle sein.
Interessiert an weiteren Entwicklungen? Besuchen Sie unsere Plattform itboard.ch für aktuelle Informationen und spannende Einblicke in die IT-Branche.
ITBoard Redaktion
itboard.ch